时序分析
啥是平稳序列?
基本上在某个固定值上下波动,无趋势,无规律,随机的。定义上“平稳”指固定时间和位置的概率分布与所有时间和位置的概率分布相同的随机过程。其数学期望和方差这些参数也不随时间和位置变化。
非平稳序列:包含趋势、季节、周期,或者参揉好几种成分,比如趋势+季节。
周期性,主要是因为时序源于计量经济,经济就是很多都有年的周期性。
时间序列的分解:我感觉就是从序列中分离出那些周期、趋势。
平均增长率:
有负值不宜算平均增长率,无意义,都得是正数
时序预测
步骤:
1、先确定你丫是什么类型的序列,比如周期的、趋势的
2、确定与1中对应的预测方法,确认这个方法
3、对候选的方法进行评估,找出最优的
4、用找出的最优的方法进行预测
1、类型的序列的确认
1、看看有无趋势和趋势的类型
有趋势不?如果有,是线性的,还是分线性的?
线性的好说啊,用线性拟合啊,然后对系数显著不为0,做假设检验啊。
线性OK了,可以用2次函数拟合,如果效果更好,说明二次拟合更合适啊。
2、看看有没有季节成分?
需要一个手段:年度折叠时间序列图:横轴就是1年,不同年的画在一起,纵轴还是对应值,说白了,就是把不同年的拍到一起。
如果有周期性,就会有交叉,
如果有周期性还有趋势,就会是折线会有向上向下的趋势,形态不变
2、选择预测方法
你预测,肯定是认为序列是有规律,且,会保持,对吧?
常见方法:
- 简单平均
- 移动平均
- 指数平均
- 自回归(ARMA)
方法选择:
- 有趋势
- 有季节性:季节多元回归、季节自回归、时序分解(有趋势、有季节)
- 无季节性:线性趋势预测、非类型的序列、自回归预测(无趋势、无季节)
- 无趋势
- 有季节性:季节多元回归、季节自回归、时序分解(无趋势、有季节)
- 无季节性:简单平均、移动平均、指数平滑(无趋势、无季节)
联想:短信发送呈现,无趋势、有季节(实际上是每天、每周、每月),但我不是要预测,我是为了要找出异常点,但是,可以参考时序分析。
3、预测方法评估
要看预测误差,有以下几种:
- 平均误差
- 平均绝对误差
- MSE均方误差
4、平稳序列的预测
1、简单平均法:,适合平稳的无周期的
2、移动平均:比简单平均用所有的数据,移动平均只用前N个值
3、指数平均法:,其中是t期的预测值,是t其值。
例:
→1,越更“吸取”最近的信息,→0,越“忽略”最近的信息。
分离复合序列
1、确定时间周期,用每个时间点上的值 ➗ 季节指数,消除季节性
2、然后对消除了季节性的序列进行预测
3、用预测值,再乘以季节指数,得到最终的预测值
分解模型为:,T:趋势,S:周期,I:随机、不规则波动
时间序列可以分解成多种模型:加法模型、乘法模型,乘法模型比较常用。
季节指数,有多种计算方法,书里只给了“移动平均趋势剔除法”
具体方法:
1、计算移动平均值,用N=4的移动平均
2、对1中移动平均再做N=2的移动平均,书上叫“去中心化处理”,得到“中心化移动平均值CMA”
3、用原有值➗中心移动平均值,得到季节比率
4、计算出季节比率的各个季度(月份)的平均值
5、4中的季节比率季度均值,
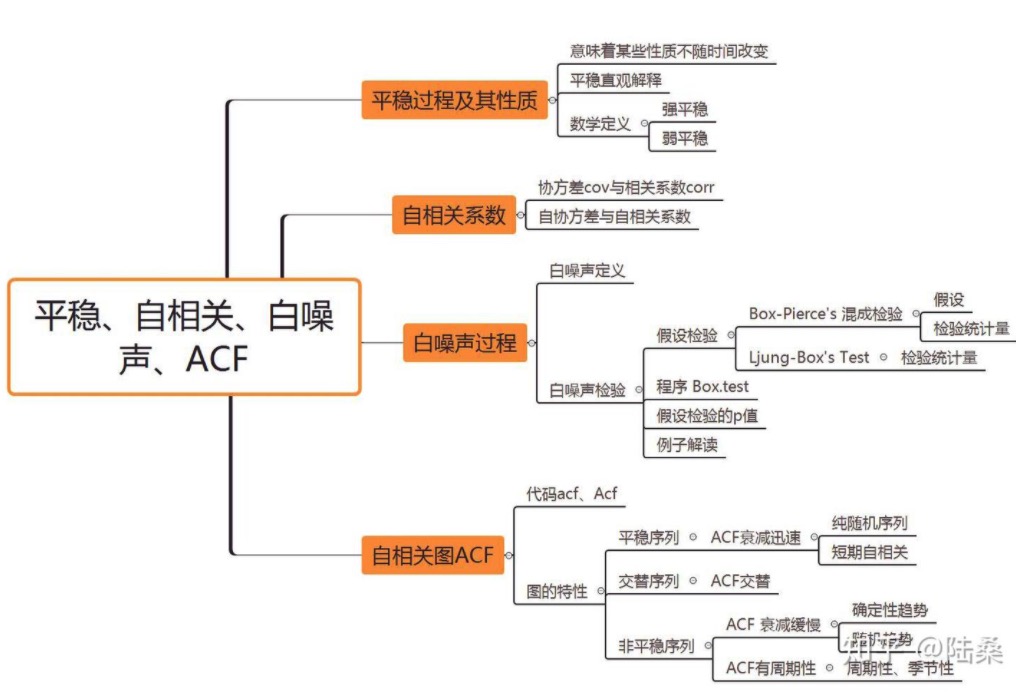
自相关AMAR
知识点:
自相关性
时间序列这种数据的特点是一维,勇往直前永不回头。根据这种数据特点,形成了自协方差、自相关函数、偏自相关函数等。看到前面都加了一个自,原因是时间序列没法找到一个别的数据和自己来进行比较;只能自己和自己来比较(Yt , Yt+k)
说白了,就是这个时间点,和下k个(可以是1,也可以是n)的相关性。
本来协方差定义是:
统计里,用样本来近似代替:
现在,自协方差,就变成了:
k是个超参。
自相关函数 autocorrelation function(ACF)
样本的相关系数(也叫样本的皮尔逊相关系数r)
现在,我们看时序序列的自相关系数r为:
自相关图 correlogram
把k取0~10,就可以得到11个,就可以画出自相关图,是个柱线图。
例:
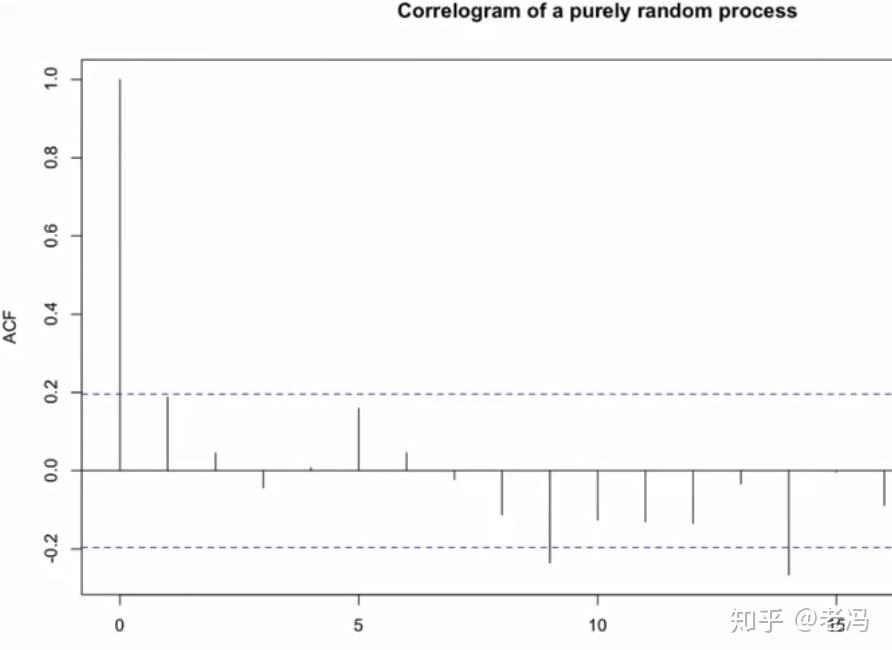
【示例】可以看一些序列的自相关图:
白噪声检验
图检验法
1.根据纯随机性序列的均值为0、协方差为0的性质,直接观察时序图是否满足均值为零
2.观察ACF自相关图,如果序列不与历史时刻序列存在自相关关系,则可认为是随机性序列
3.残差序列的QQ图:若残差满足正态性假设,残差序列为正态白噪声过程或高斯白噪声过程。残差序列的Q-Q图近似为过原点的一条直线,则残差服从正态分布且均值为零
统计检验法
1.混成检验
就是,检验这个序列是不是一个白噪音,白噪声一点用没有,如果是,就不玩了
咋检验?其实就是看,每个k,比如上面,是不是都0,都是0,那么这个序列就是个白噪音,就是平稳的。
大致意思是这样,但是也不是那么简单,看看都为0,还是要通过构建统计量,然后做假设检验:
统计量为:
这里,,是样本的k阶滞后的自相关系数,这玩意是符合自由度为h的卡方分布
这里啰嗦几句,你直接看为0不就得了,不行,因为这个是样本,不是全量数据,只是一种样本抽样,对全体的推测。
给定显著性水平,则拒绝域是。接受原假设意味着,认为原序列是白噪声序列,否则认为序列存在相关性。
大部分软件会给出Q(H)的p-value,则当p-value小于等于显著性水平 α时拒绝
2.Ljung-Box test(LB 检验)
对混成检验的检验统计量做了修正,更接近卡方分布
平稳性
平稳性定义
严平稳:间隔时间时间的概率分布完全一样
宽平稳:放松啦,不要求概率分布完全一样,只要求:均值常数、方差常数、协方差常数且仅依赖于时间跨度。
时间序列认为每个时间点都是随机变量,而每个变量只有一个样本观察值,我们要运用数理统计方法——样本估计总体,从一个总体也就是一个随机变量中抽取若干个样本观测——就毫无办法。而时间序列又可列多个变量,每个变量在观测的历史进程中都只出现一次,如果时间序列不平稳(随时间的平移而变化),每个变量的均值、方差都只能用一个观察值去估计,效果肯定不佳。但如果时间序列是平稳的,就可以将多个随机变量看做来自相同的总体,他们的观察值就可以看做从同一个总体中抽出的样本,这样就可以利用经典的数理统计方法进行处理。
讲人话:因为是稳定的(啥是稳定来着?均值常数、方差常数、协方差常数),所以,不同时间点的单独的样本可以视为来自同一总体(分布相同),不平稳就没法这么假设了。
平稳性检验
那问题来了,如何知道一个序列是不是平稳的,还有两种方法来考察他:
- 图检测法:时序图、PP图、ACF图
- 统计检验法:ADF检验(增广DF)、PP检验(单位根检验)、KPSS检验
AMAR
参考:《金融时间序列分析讲义》
终于可以说说AMAR了,他是用来预测的,前面都是讲如何去判断序列的特性,都是为了预测做准备,我们知道序列又如何?我们最终目的还是为了要预测未来。
流程图:
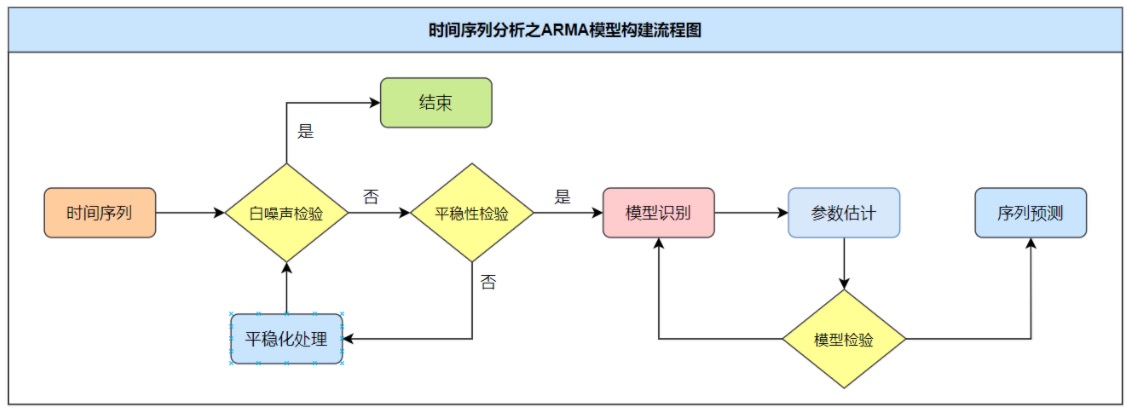
AR
AR模型的思想非常的朴素,认为当前的结果与之前的结果相关,简单的来说当前的结果等于历史数据的加权平均,然后再加上当前时刻t 的一个扰动,我们只需要算出各个参数就可以了。
MA模型
MA模型的思想也非常的朴素,认为当前的结果x_t与之前的扰动相关,简单的来说就是认为x_t主要受过去q期的误差项影响,即当前的结果等于历史扰动的加权平均,然后再加上历史结果的均值μ,我们也是只需要算出各个参数ϕ 就可以了。这个也非常好理解,如果咱们的数据是在均值附近不断波动的,是什么让数据波动的呢?就是扰动项,扰动使得数据不断的变化,最终变成当前的数据:
x_{t}=\mu+\varepsilon_{t}-\theta_{1} \varepsilon_{t-1}-\theta_{2} \varepsilon_{t-2}-\ldots \ldots \theta_{p} \varepsilon_{t-q}
ARMA模型
ARMA模型是最常用的平稳序列拟合模型,随机变量的取值不仅与以前p期的序列值有 关还与前q期的随机扰动有关。
参考
- Time Series Analysis - 時間序列模型基本概念:AR, MA, ARMA, ARIMA 模型
- 时间序列分析——自回归移动平均(ARMA)模型
- ARIMA模型详解
- 第 8 章 ARIMA 模型
- 时间序列分析教程(三):ARIMA
- 【时序预测】一文梳理时间序列预测——ARMA模型←这篇写的最好,未来需要的话,可以来读
暂时,不整理了,《金融时间序列分析讲义》 讲的虽然好,但是,太过晦涩,我读起来费劲,不如上面几篇,帮助我很快的理解,本打算写一篇博客,没有时间,未来可以捋着这几篇的思路,再复习一遍,写一篇博客和输出把,就此打住!20211208
平稳性的评估很重要,让我们知道在多大程序上历史数据可以用来预测未来数据
时间序列是否存在一些内部动态关系(例如季节性变化),也叫自相关性
最后,我们需要确保我们找到的关联是因果关系,而不是虚假的相关性
平稳的时间序列指的是这个时间序列在一段时间内具有稳定的统计值,如均值,方差
建议平稳性的方法:
1、Augmented Dickey Fuller Test (ADF Test),是单位根检验(unit root test)的一种
它实际上是检验中的系数等于1。
他的缺点:
- 数据点少,容易假阳性
2、Kwiatkowski-Phillips-Schmidt-Shin (KPSS) test也是常用的时间序列平稳性假设检验
KPSS的原假设是关于平稳过程,而ADF的原假设是关于单位根
时间序列平稳性的重要性:
- 大量的统计学模型基于平稳性的假设
- 对于一个应用于非平稳时间序列的模型,它的准确性和模型指标会随着时间序列本身变化而变化,从而造成模型本身不稳定。
非平稳的时间序列变换成平稳性:
- log变换(适用于非等方差)
- 平方根变换(适用于非等方差)
- 差分的方式