参数估计
前面讨论了,用抽样样本,可以构建出“统计量”,用统计量,是不是可以反向估计出整个总体的特性呢?要是能,该多好啊!
我先斗胆、朴素、naive地估计一下:用样本均值,去估计总体的均值?用样本的方差去估计总体的方差?成不?
成!
点估计
这种方法,就叫做“点估计”。
虽然,理论上,你抽样的均值的期望等于总体的均值,讲人话,就是,你抽无数次,抽出个无数次的样本的均值,这些均值,最终的期望是真实总体的均值:
但是,你不可能抽无数次,你的随机和偶然性,必然导致你用这些个抽样均值,去代表总体均值,是不准确的。
那么问题来了,“不准确的”,这种话就是屁话,有多不准确?你能给我一个量化的数么,概率也行啊。
答案是,不行!点估计给不出,所以,要引出区间估计。
区间估计
与点估计不同,点估计出一个值,区间估计给出一个范围。且,给出总体的值(比如总体的均值),落在这个区间的概率。
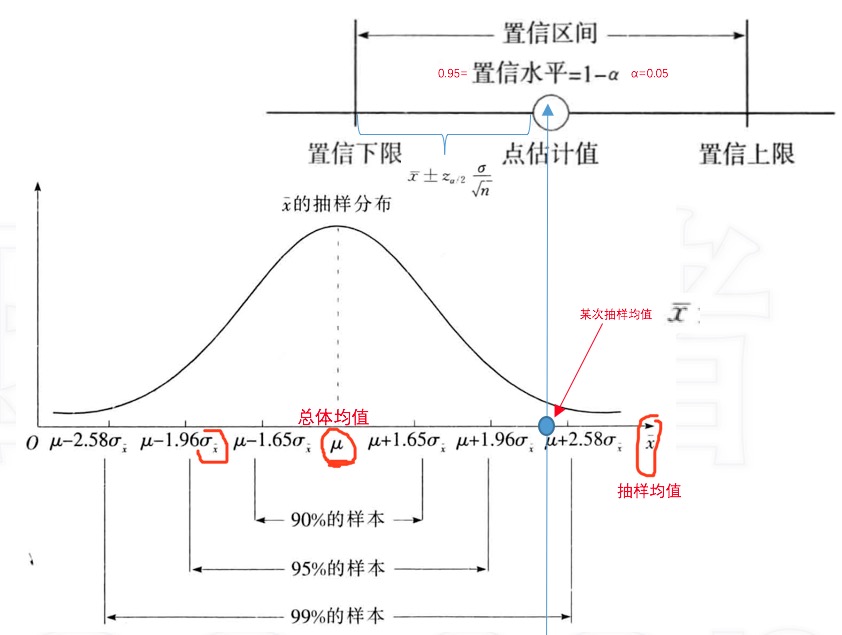
还记得,前面的中心极限定理不?
均值为,方差为的总体,抽样n个样本,n足够大的时候,样本均值的抽样分布,近似符合方差为,方差为的正态分布。
我噻!看到正态分布了!为何我这么激动,有一个可以确定的分布了啊,我就能干好多事儿了啊。
来!我们来看看这个正态分布:我问你,这个正态分布的随机变量是是谁?是抽样的均值!别晕! 你抽一次(抽出100个样本),你算个均值出来,这个均值,就是一个随机变量的值;然后你再抽100个,又得到一个;你再抽、再抽、... 然后,你落在3个方差之外的概率是95%啊,我勒个去,给出了“落在这个区间的概率”了(就是前面提出的问题)。
这里千万别晕,你其实是不知道总体的的,对,你不知道;你知道只有一次次抽样的均值,我管它们叫:抽样均值1,抽样均值1,抽样均值1,...,它们是一组随机变量的值,对吧?
接下里的描述,太精妙了,我不自己组织语言了,我引用书上的话吧:
我们可以求出样本均值落在总体均值的两侧的概率,但是,实际估计时候,我们只能知道,我们反倒是不知道,它恰好是我们要求的东东。 如果样本的均值落在总体均值的两个总体标准差内,那么你也可以说成是,总体样本的均值是落在样本均值的两个总体标准差之内。 比如,用100次抽样出来的100个均值,有95个的样本均值+2个总体标准差范围内,包含了总体样本的均值。
大白话说出这事,就是,哥们我抽样了1次,抽了N个(这个数不重要),得到一个均值,我现在就可以拍着胸脯说,兄弟,你这个均值,你左右探出去总体方差(但是,你不知道啊这个哈,强调一下),这个区间内,总体样本的均值落在里面的概率是95%。
这里,我们一直都不知道总体样本的均值和方差啊,再次强调一遍,别晕,我们就是要求他们俩,但是,我们为了求他们俩,我们去抽了100次的样,得到了100个样本均值,我们只能用这些均值,来反向告诉别人,总体样本均值,大概是落在这里面,多大概呢?那就得知道总体样本的方差啊,可是这玩意,我不知道啊。不过,我看书上说,如果知道,就可以直接套用(我就奇了个怪了,您总体均值都待定呢,咋个就知道方差了呢);如果不知道,就可以用抽样样本的方差来近似代替,别急,前提是样本数量n要足够多,一般要求n>30。
再说一下这个置信区间怎么求呢?
你可能说,用我估计的均值,加上2个标准差,不就是了么?
这里有几个问题:
1、为何加2个标准差,不加1个,或者3个?
答:这个需要反着想,你给出一个所谓的,没有中文对应名字,但是有,叫置信水平,啥叫置信水平,就是个概率值,是你这个样本均值中包含真实的总体样本均值的概率。如果这个是一个正态分布,可以反向求出对应的概率的对应的x值, 这个值叫做“”。
多说一句,这个,实际上是标准正态分布对应的x,为何是标准正态分布呢?
对正态分布做变换成为标准正态分布,目的为了方便查表求。
所以,给定了置信水平对应的,就可以查表求出,然后就可以得到对应的置信区间了。
吐槽一下,为何叫z呢,因为,对应的是标准正态分布,就是用z来表示的,哈哈。
2、这个标准差是啥?是样本的标准差么?还是总体的标准差?如果总体的标准差不知道呢?
这个标准差,是总体的标准差,如果总体样本的未知,可以用抽样数大于30的样本方差近似代替。
3、说我的置信区间包含真值的概率是,这个说法对不对?
不对!书上专门强调了这点。很多时候,我们只做一次抽样,得到一个确定的置信区间(给定置信水平\alpha的要求后),总体均值,也是确定的,这个时候,置信区间和总体均值,之间就是包含、不包含,二选一。他不是个概率问题!但是,如果你抽样100次,给定同样的置信水平的情况下,就得到次包含总体均值的情况。所以,需要这样理解才精确。
不过,我觉得,你认为置信水平就是“置信区间包含真值的概率”,也没啥大问题,无关大雅,个人的感觉。
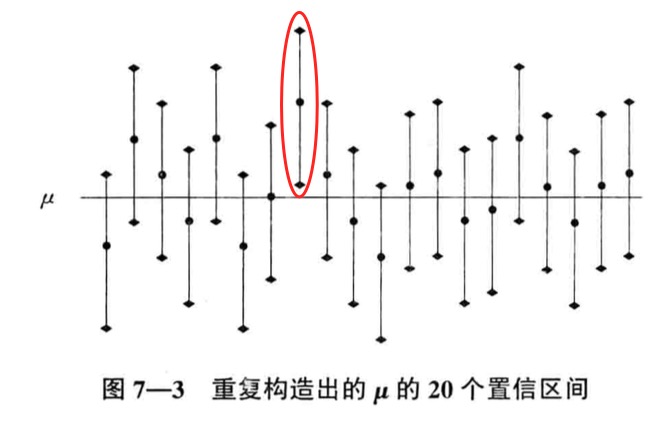
做了20次抽样,得到20个置信区间(每次给定一个置信水平0.95),有一次“不幸”漏掉了总体的均值。
评价估计量
说道估计参数,比如总体的均值,你用的是样本的均值这个统计量,那你为何不用抽样样本的中位数呢?可以啊,你完全可以用,但是,效果肯定不如抽样的均值好。
这就涉及到一个话题,你如何评价一个统计量,是不是一个更好、最好的统计量,这里有3个原则,来评价他们:
- 无偏性
这个意思就是说,是总体的参数,是估计量,这意思是说,你用来估计的统计量,他们的均值,应该等于真实的你要估计的总体的那个参数,这就叫无偏性。“我估的和真实的总体参数一样”。
- 有效性
另外,你的统计量,和我的统计量,咱俩都具备无偏性,但是,我的方差小,你的方差大,那我的就比你的好,也就是说,估计量(统计量)的方差更小的,更有效,这个特点叫有效性,“我比你有效”。
- 一致性
假设某个统计量(估计量)是个无偏估计,你用100个抽样的均值去估计真实总体均值,得到一个方差;然后你用1000个继续估计,应该到的方差更小。n越大,和真实总体的参数的方差应该越小,这个特性就叫一致性。“n越大估的越准”。
抽样数量
一个很重要,但是被前面一直忽略的问题,就是,需要抽样多少个样本,才能比较好的估计出来总体呢?
总结
总结一下,用样本均值直接当做总体均值,这方法叫点估计,不好。
用区间估计,可以给出某个置信度(),也即是相信总体的均值(是个确定值)落在某次抽样均值 区间概率是置信度()。